I gave a talk on Tuesday at the “Gems of Theoretical Computer Science” seminar on the LLL algorithm.
Abstract:
The LLL (Lenstra–Lenstra–Lovász) algorithm is a lattice reduction algorithm that can approximate the shortest vector in a lattice, and has numerous applications (which I’ll cover as time permits), including polynomial-time algorithms to
- factor polynomials over the rationals
- given an approximate root of a low-degree rational polynomial, recover the polynomial
- find integer relations such as
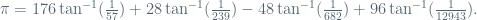
- solve integer programming in fixed dimension
- break certain cryptosystems.
Notes from the talk are here (TYPO on pg. 3: the example at the bottom should be [[1, .3, 4.2], [0, 1, -.3], [0,0,1]] -> [[1, .3, .2], [0, 1, -.3], [0, 0, 1]]. I didn’t get to cover all topics). Quick summary:
- The goal is to find the shortest vector in a lattice. The LLL algorithm draws inspiration from 2 simple algorithms, the Euclidean algorithm (1-D case; it has a “reduce” and “swap” step), and the Gram-Schmidt orthonormalization process (to generalize to higher dimensions). A reduced basis comes “naturally” from making an algorithm that does a “reduce” and “swap” steps. The LLL algorithm only gives an exponential approximation, but this is good enough for many purposes.
- The algorithm terminates because smaller vectors filter to the front; create a invariant out of that.
- A closely related problem is the Closest Vector Problem. Solve it by moving the point to a fundamental parallelopiped of the reduced lattice.
- The LLL algorithm can be used to find integer relations between numbers given sufficiently good approximations. Applying this to powers of an algebraic number, we can recover the minimal polynomial. Applying this to roots of a polynomial we can factor the polynomial.
- The algorithm for Closest Vector can solve Integer Programming in fixed degree, by recursion on the dimension. Bounds on the size of the basis elements in a reduced basis bounds the number of hyperplanes cutting the convex set.
- LLL can break RSA with small exponent by finding roots of polynomials mod N of small degree.
Some more resources are the following:

